[tweetmeme]If you have no idea on how to start scraping the web with Python, then read on. The first small step is simpler than I thought it would be.
By: Martin Ove
This post will teach you how to fetch the HTML of a website using Python in windows. This is as far as I have gotten at this time, and even though it isn’t really useful yet, I guess it’s the first step towards webscraping with Python.
First of all you need to get Python on your computer.
(Update 24.12.2010 – Be sure to check out Thomas’ comment after this post if you’re using Python 3.1. Some statements have changed. Thanks Thomas!)
1. Go python.org/download/ and download Python. I use 2.7 for windows.
2. Install it. Mine is installed at c:\python27\
Now you’re all set. Let’s fire up Python.
3. Go to your start menu and find the folder called “Python 2.7”. Click “IDLE (Python GUI)”
You should see something like this:
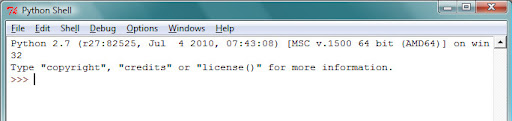
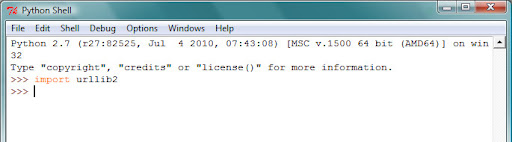
4. Type up “import urllib2” and press enter. If all is well, nothing will happen and it will look like this:
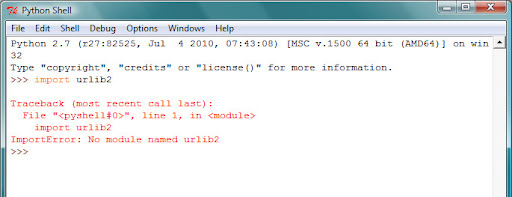
If something is wrong, you’ll see something like this. Make sure to check for typos:
5. Type up “response = urllib2.urlopen(‘http://martinove.dk/test/example.html’)” and press enter. This will get the source code of the page as a file, but it won’t look like anything happened.
6. Type up “html = response.read()” and press enter. This will read the response you got from the webpage and assign it to the variable “html”. Expect no response other than a new line.
Here comes the magic though.
7. Type “print html” and…*drumroll*… enter!
If all goes well, you should see the source code of http://martinove.dk/test/example.html. It’s very small and made for this purpose.
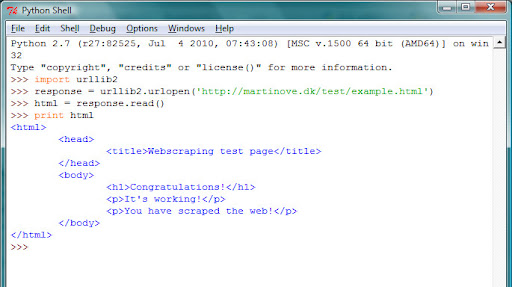
Feel free to try out other urls while you’re at it.
That’s it for now. In the future I’ll fool around with parsing the HTML using BeautifulSoup You can read a lot more about how to fetching HTML here:
HOWTO Fetch Internet Resources Using urllib2
If you have any question be sure to just throw them at me.
Thanks for reading.
{kind=link}
Leave a Reply